Die Evolution der Metadatensammlung hat viel mehr an Automatisierungsgrad gewonnen. Nicht nur in den Unternehmen sondern auch im privatem Umfeld.
Metainformationen sind strukturierte Daten, die Informationen über Merkmale anderer Daten enthalten. Beispielsweiße können mit Metadaten Antworten auf folgende Fragen geliefert werden:
- Was sagt ein Datenelement aus?
- Wer hat die Daten angelegt?
- Wann wurden die Daten erstellt?
- Wer ist der Eigentümer?
- Wer hat die Daten zuletzt geändert?
- Wo ist der Ursprung dieser Daten?
Nur wie kann man solche Metadatensammlung auswerten? Das gute an Metadatenmanagement ist es, dass solche Informationen überwiegend vorliegen sobald Daten persistiert werden. Der Einsatz solcher Auswertungen können sich in großen Datenlandschaften, wie zum Beispiel ein Data Warehouse auszahlen.
Tools wie das Informatica Enterprise Data Catalog bieten hier sogenannte Daten-Scanner, die die Metadaten aus angegebenen Datenpools wie z. B. eine Datenbank abziehen und zur Auswertung bereitstellen. Natürlich können die Metadaten im nachhinein durch äußere Aktionen angereicht werden, wie z. B. durch manuelle Kommentare, bei dem die zuvor konfigurierten Data Owner auch benachrichtigt werden können. Hierzu werden die verschiedensten Scanner angeboten, welche auch unstrukturierte Datenbeständen abziehen und auswerten können.
Des Weiteren wird dem User auch die Möglichkeit angeboten, sogenannte Custom Metadata Informationen in die Auswertungen hinzuzufügen. Dies sind Informationen die durch den Scanner nicht gelesen bzw. erkannt werden können. Beispielsweiße wären das Berechnungen innerhalb Datenbewirtschaftungsprozesse, welche als „Blackboxen“ dargestellt und beschrieben werden können.
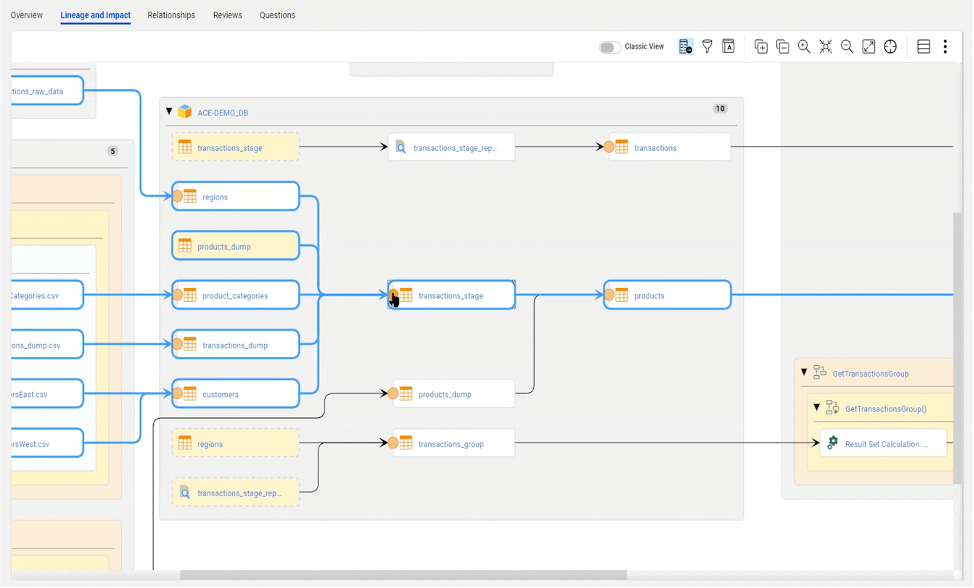
Die Kernfunktion solcher Enterprise Tools liegen hauptsächlich in der Auswertung der Daten als Lineages. Hier werden die Prozessketten bzw. die Abhängigkeiten der Daten grafisch dargestellt bzw. gerendert. So kann ab jedem Datenelement die Herkunft und der Weiterverlauf analysiert und nachvollgezogen werden. Das Detailierungsgrad nimmt abhängig von der Sicht auf das Lineage zu. Je weniger Detailierung um so mehr aggregiert wird das Lineage dargestellt.
Durch das Metadata Management entstehen neue Sichten auf die eigene Datenlandschaft und die Unterstützung zu Entscheidungsfindungen bei fachlichen und technischen Fragen auf das Gesamtsystem. Durch Herkunfts- und Wirkungsanalysen können Aufwände bei Anpassungen am System besser eingeschätzt werden. Außerdem kann die Herkunft und Zuständigkeit der Daten schnell identifiziert werden. Das Metadata Managment bietet einen großen Nutzen und eine Vielzahl von Vorteilen wie etwa die Tranzparenz in Komplexen Datenprozessen, Unterstützung IT & Fachbereich, Reduktion von Datenanalysen und Entwicklungszeiten, Zusammenarbeit und ein einheitliches Vokabular aller Benutzer egal ob aus der IT oder dem Fachbereich.
Aykut Celik